


























Z perspektywy klienta, system jest zbiorem funkcji zaspokajających jego potrzeby. Dostawcy systemów konstruują je w taki sposób, aby dostarczyć tych funkcji przy jak najmniejszym zużyciu zasobów i to zarówno w trakcie samego tworzenia systemu, jak i w trakcie jego działania. Aby osiągnąć na tyle dobre wyniki, aby system odniósł sukces rynkowy, twórcy systemów stosują, odpowiednio do zbioru funkcji (wymagań), specjalizowane architektury. Architektura dużego systemu jest zazwyczaj wielowymiarowa, mamy warstwy fizyczne, warstwy logiczne, dzielimy systemy na moduły kompetencyjne, powstają platformy komponentowe pozwalające na łączenie wielu rozwiązań w jeden spójny system. Wszystko to, cały ten skomplikowany inwentarz, angażujemy wyłącznie po to, aby dostarczyć odbiorcy wymaganych funkcji.
Czym zatem jest funkcja, którą realizuje system? Rozważmy prosty schemat:
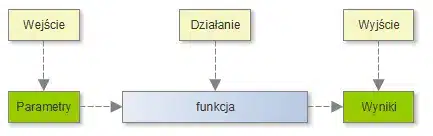
Schemat ten, w zadziwiający sposób przypomina pojęcie funkcji, które znamy z lekcji matematyki. Zmieniając go nieznacznie, otrzymujemy:
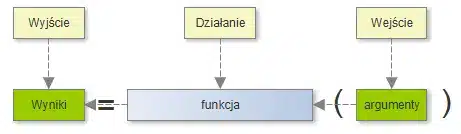
czyli coś, co już zdecydowanie przypomina szkolne:
y = f (x)
Skoro tak jest to czy system nie mógłby się w całości składać z funkcji? Znaczną część swojego zawodowego życia uważałem, że nie, nie mógłby, jednak ostatnie moje kontakty i doświadczenia z językami funkcyjnymi pozwalają mi zacząć inaczej patrzeć na to zagadnienie.
Zacznijmy od wyjaśnienia, dlaczego funkcje nie wystarczą. Otóż czyste funkcje, a o takich tu mówimy, mają pewne cechy, które w zasadzie uniemożliwiają zbudowanie systemu wyłącznie opartego o nie same. Jak widzimy na schemacie funkcja „karmi się” argumentami, które do niej przekazujmy, oraz wynikiem jej działania są wyłącznie te wyniki, które nam zwraca jako efekt swojego działania, z tego wynika zasada, że funkcja nie powinna powodować
żadnych efektów ubocznych
Zastanówmy się więc czy tworząc system, możemy sobie na to pozwolić. Pierwszym kandydatem na obalenie tej tezy jest wszechobecne w systemach informatycznych wejście i wyjście. Zapis pliku na dysk, wyświetlenie czegoś na ekranie, odczytanie klawisza z klawiatury, wysłanie zapytania do bazy danych, to wszystko są przejawy komunikacji z podsystemem I/O, i wszystko to są efekty uboczne działania funkcji. Uogólniając, funkcja podczas swojego działania poprzez np. I/O czyta i zmienia stan systemu, a nie tylko zwraca wyniki swojego działania. W tym ujęciu efekty uboczne działania funkcji w systemach informatycznych są powszechne i nie można sobie wyobrazić systemu, który bez nich będzie działać.
Niby porażka, ale zastanówmy się, gdyby, funkcje nie modyfikowały stanu systemu, a wyłącznie otrzymywałyby na wejście aktualny stan oraz w parametrach wyjściowych zwracałyby zlecenia zmiany tego stanu. Sama funkcja nie miałaby żadnych efektów ubocznych, a pełnie zadań związanych z obsługą stanu przejąłby na siebie kontener:
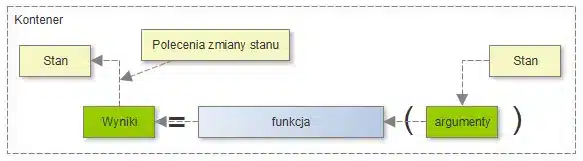
Wygląda to dobrze, ale zdefiniujmy pojęcie stanu systemu, co to właściwie jest, może to być np. jakaś forma trwałego magazynu informacji, np. baza danych. Przekazanie bazy danych do funkcji, cokolwiek miałoby to oznaczać, wydaje się dziwne, napotykamy tu przeszkodę, którą można nazwać:
zmienność stanu w czasie
Przekazanie argumentów do funkcji powinno być związane z ich niezmiennością w trakcie działania funkcji, aby funkcja mogła działać prawidłowo, argumenty powinny być
obiektami niezmiennymi
Niestety stan systemów zmienia się z ogromną częstotliwością i jako taki nie może być traktowany jako niezmienny.
Niby kolejna porażka, ale zastanówmy się, gdyby jasno określić, jakiej części stanu funkcja potrzebuje i te dane odczytać i przekazać do funkcji już w postaci niezmiennych obiektów. Wygląda to kolejny raz dobrze i powinno dać się zrealizować. Przypomnijmy jednak, że:
stan systemu się zmienia
Nasza funkcja będzie działać na pewnej migawce stanu, na stanie, który był prawdziwy w chwili jego pobrania przez kontener, a nie na stanie aktualnym, polecenie zmiany stanu, które zwróci funkcja, mogą być już „nieświeże”, bo stan systemu „pogalopował” już do przodu. Znowu problem i znowu porażka!
W takiej sytuacji mamy dwa klasyczne i dwa mniej klasyczne rozwiązania, z klasycznych:
– zamrozić tę część stanu systemu, która przekazujemy do funkcji do czasu realizacji poleceń zmiany systemu, które zwróciła funkcja. Rozwiązanie to zwane blokowaniem pesymistycznym polega na zastosowaniu różnego rodzaju blokad, semaforów, specjalizowanych poziomów separacji transakcji („repeatable read”, czy wręcz „serializable”), wszystkie mają jedną wspólną cechę, zmniejszają współbieżność,
– lub założyć, że stan systemu się nie zmieni, lub że bardzo rzadko to się może zdarzyć, a przy stosowaniu zmian sprawdzić, czy się zmienił i jak tak to wycofać działanie funkcji, metoda zwana jest powszechnie blokowaniem optymistycznym i ma jedną wadę, jeżeli stan systemu zmienia się często to mamy problem znaczną ilością funkcji kończących się błędem.
Z mniej klasycznych:
– jedno jest o tyle banalne co oczywiste, polega na nie posiadaniu stanu współdzielonego, czyli takiego, który chciałyby zmieniać jednocześnie różne funkcje w systemie. Przy takim rozwiązaniu można blokować optymistycznie albo wręcz wcale nie blokować, bo z architektury wynika, że każda funkcja zwraca polecenia modyfikacji wyłącznie własnego niezależnego o innych stanu,
– banał powyższego może śmieszyć, jednak wiele systemów spełnia bez problemów te założenia. Co jednak gdy tak nie jest i mamy stan współdzielony. Można zastosować rozwiązanie polegające na addytywnej czy pośredniej modyfikacji tego stanu, co to oznacza, pewne elementy tego rozwiązania opisałem w artykule „Update na Insert”, gdzie zmieniamy czynność modyfikacji stanu (zazwyczaj blokującą) na opublikowanie zdarzenia zmiany stanu o pewną deltę. Jednocześnie zmieniając sam algorytm pobierania stanu na pobranie, plus uwzględnienie delt, co pozwala uniknąć blokowania.
Czyli można? Można ! 🙂
Czy zastanawiacie się (tak jak ja), po co tyle zachodu? Otóż składając system wyłącznie z funkcji (oczywiście działających w kontenerze i radząc sobie ze stanem współdzielonym), otrzymujemy system, który posiada dużo niebanalnych zalet: praktycznie nieograniczona skalowalność, duża łatwość automatycznego testowania, łatwe keszowanie wyników, proste nieblokujące się algorytmy, łatwość monitorowania i zarządzania. Idąc tym tropem, zachęcam do zapoznania się z założeniami programowania funkcyjnego, jest to dzisiaj modny i w wielu przypadkach uzasadniony paradygmat programistyczny, zdecydowanie wart poświęcenia mu dłuższej chwili uwagi.

Krzysztof Olszewski
Dyrektor Technologii i Architektury Oprogramowania
Krzysztof Olszewski
Dyrektor Technologii i Architektury Oprogramowania