


























Najprostszym i niestety najczęstszym podejściem do tworzenia usług, jest budowanie ich interfejsu w oparciu o metody jednostkowe. W tym ujęciu, usługa pozwalająca na sprawdzanie statusu zamówienia w sklepie internetowym miała by interfejs
OrderStatus getOrderStatus(OrderId id)
Implementacja takiej usługi będzie najpewniej oparta o pobranie statusu z trwałego magazynu danych. Gdyby była to relacyjna baza danych, to skończyło by się to zapytaniem SQL w postaci
SELECT o.status FROM order o WHERE o.id = :id
Nic w tym dziwnego, nic zaskakującego. Przyznajmy się sami przed sobą, jak często z takimi implementacjami się spotykamy, jak często sami takie tworzymy.
Podejście takie to początek „czystego zła”. Zło to ujawnia się w pełni kiedy klient usługi chce z niej skorzystać wiele razy, wtedy kiedy zamówień jest wiele. Pierwsze rozwiązanie które mógłby zalecić dostawca usługi to zalecić wywołanie metody getOrderStatus() tyle razy ile potrzeba. To takie proste i szybkie, w dodatku nie wymaga zmian w systemie dostawcy usługi. Gdybyśmy jednak chcieli obliczyć czas realizacji takiej złożonej operacji to okaże się, że trwa ona tyle ile pojedyncza operacja tylko tyle razy więcej ile razy ją wywołaliśmy, czyli
Czas = ilość wywołań * czas jednego wywołania
w skrócie
T1 = N * call()
gdy uświadomimy sobie że dla usług sieciowych czas jednego wywołania obciążony jest każdorazowo czasem przesłania żądania i odpowiedzi po sieci, które zdecydowanie nie są do pominięcia, to szybko zgłosimy dostawcy usługi że potrzebujemy metody podobnej do
List<OrderStatus> getOrderStatuses(List<OrderId> ids)
Dostawca usługi (tracąc czujność), szybko dostarcza nam implementacji w stylu
List<OrderStatus> getOrderStatuses(List<OrderId> ids) {
List<OrderStatus> statuses = new ArrayList<>();
for (OrderId id : ids) {
OrderStatus status = getOrderStatus(id);
statuses.add(status);
}
return statuses;
}
Przecież nie będzie tego pisał od nowa, wywołuje więc w pętli wcześniejszą implementację. Pozornie mamy pełen sukces. Jednak patrząc na czas trwania tej nowej metody z punktu widzenia dostawcy usługi to dalej jej czas trwania to
T2 = N * call()
choć sam call() nie jest już obciążony ruchem sieciowym, to jednak dalej jest słabo. Dodatkowo, w logu bazy danych, administrator widzi lawinę bardzo podobnych, wspomnianych wyżej, zapytań SQL. Coś jest nie tak.
Z pomocą przychodzi nam całkiem inne podejście które zakłada od samego początku, że zamówień może być wiele i dostawca usługi od zaczyna od interfejsu zawierającego metodę
List<OrderStatus> getOrderStatuses(List<OrderId> ids)
i w konsekwencji jej implementacji, która powoduje, że niezależnie od ilości zamówień do sprawdzenia do bazy danych idzie jedno (sic!) zapytanie SQL o kształcie
SELECT o.id, o.status FROM order o WHERE o.id IN (:ids)
klient usługi będzie bardzo (choć pozytywnie) zaskoczony. Metoda ta w jakiś zadziwiający sposób działa podobnie szybko dla jednego jak i dla dziesięciu czy dwudziestu zamówień, czas jej wzrasta minimalnie, zazwyczaj tylko o kilka procent. W poprzednim podejściu czas rósł liniowo, dziesięć zamówień trwało prawie dziesięć razy dłużej niż jedno. Administrator nie widzi już w logach lawiny zapytań, system dostawcy usługi jakoś magicznie nie zauważa zwiększonego obciążenia nawet jak odbiorca pozwala sobie na duże ilości zamówień do sprawdzenia.
Niby pełna nirwana ale jednak znalazł się taki klient usługi który ma wyłącznie jedno zamówienie do sprawdzenia i ten interfejs mu nie odpowiada, dostawca szybko (choć odrobinę pochopnie) dodaje znaną już nam metodę metodę
OrderStatus getOrderStatus(OrderId id)
implementując ją szybko i prosto jako
OrderStatus getOrderStatus(OrderId id) {
return getOrderStatuses(Arrays.asList(id)).get(0);
}
Pięknie! Z punktu widzenia systemu mamy dwie wygodne metody w interfejsie udostępniające usługę, ale za każdym razem poprzez tą samą bardzo wydajną implementację, uznając dwie zasady
poprawna jest wyłącznie implementacja dla N argumentów
jeden argument to także N argumentów tylko wtedy N == 1
dochodzimy do reguły
T3 = call(N)
Zobaczmy wykres pokazujący czas trwania pobrania statusu zamówień w zależności od ich ilości dla naszych trzech podejść
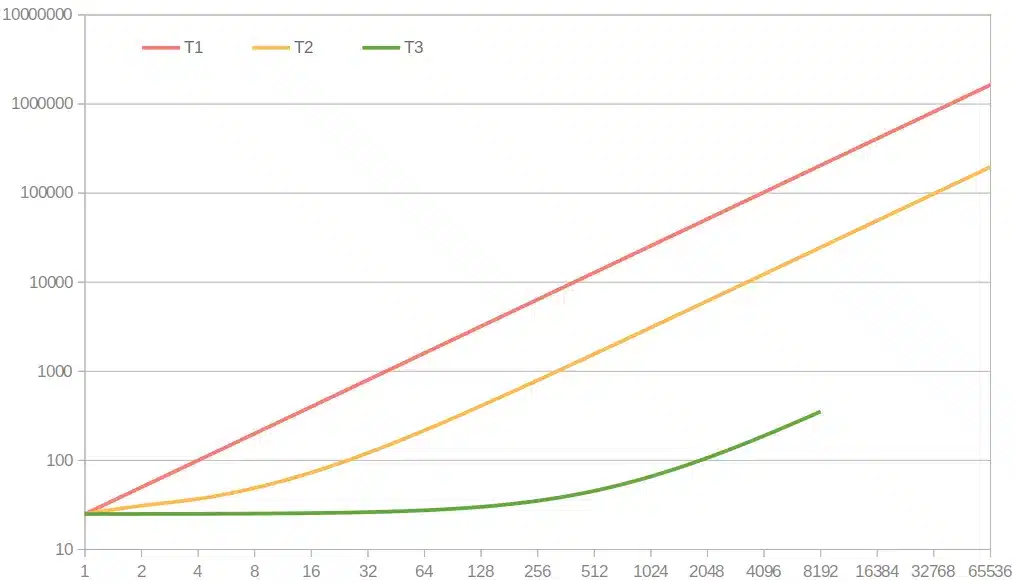
Skala czasu jest logarytmiczna, jednak wyraźnie widać prawie 10 krotną przewagę metody T2 nad T1, natomiast przewaga T3 jest tak duża że aż porażająca. Jedno co niepokoi to brak pomiarów dla T3 powyżej 8tyś zamówień, wynika to z tego że akurat ta baza danych posiada ograniczenie co do ilości parametrów w klauzuli IN i po prostu powyżej tego limitu zgłasza błąd zapytania SQL. Rozwiązaniem było by jawne i udokumentowane limitowanie ilości zamówień w pojedynczym żądaniu, albo „paczkowanie” do kilku zapytań.
Czy na kimś to robi wrażenie? Czy ktoś się tym przejmuje? Polecam przyjrzeć się zmianom w wersji 5.1 najpopularniejszego ORM’a czyli Hibernate’a. Dodano tam pewien nowy interface MultiIdentifierLoadAccess, którego użycie wygląda w ten sposób
MultiIdentifierLoadAccess<Order> multi =
session.byMultipleIds(Order.class);
List<Order> orders = multi.multiLoad(1L, 2L, 3L);
i jak się pewnie domyślamy pod spodem idzie jedno zapytanie SQL do bazy, okazuje się że nie tylko, w dokumentacji jest jeszcze mowa o
Hibernate’s implementation also provides an additional advantage: It splits huge lists of primary key values into multiple batches. This is sometimes required because some databases limit the number of elements in an IN clause
pięknie, o tym też pomyśleli. Gdyby użyć tej metody (pomijam sens czytania całych encji) to na naszym wykresie zielona linia nie kończyła by się przedwcześnie.

Krzysztof Olszewski
Dyrektor Technologii i Architektury Oprogramowania
Krzysztof Olszewski
Dyrektor Technologii i Architektury Oprogramowania