


























Kreacje nowych mechanizmów jawią się być podstawowym budulcem rozwoju systemów informatycznych. Jednak usprawnienia jako bazowy mechanizm zmian ewolucyjnych, cokolwiek posądzane o mrówczy i mało widowiskowy charakter, wg mnie stanowią prawdziwą lokomotywę postępu.
Na tym tle chciałbym opisać pewne usprawnienie wprowadzone w jednym z podsystemów platformy Streamsoft NEXT. Chodzi o widok tabelaryczny, podstawowy składnik warstwy UI a dokładniej jego podsystem wyszukiwania danych. Wyszukiwanie w widoku tabelarycznym jest już dosyć rozbudowane. Mamy do dyspozycji wiele metod z znaczną ilością parametrów i wydaje się, że w każdej sytuacji można dobrać optymalny i wydajny sposób jego realizacji. Jednak sygnały z prowadzonych wdrożeń i opinie niektórych klientów kazały nam wrócić do „deski projektowej” i poszukać alternatywnego rozwiązania. W trakcie kolejnych prac powstały trzy (aż) mechanizmy:
- Wyszukiwanie ekranowe
- Doszukiwanie ekranowe
- Buforowanie danych po stronie klienta
Wyszukiwanie ekranowe, działa w sposób bardzo prosty, w trakcie pokazania się widoku dane całego zbioru danych pobierane są do pamięci operacyjnej klienta, następnie wyszukiwanie w nim odbywa się już po stronie klienta, bez udziału serwera, za pomocą prostego przeszukiwania wartości w kolumnach traktowanych jako tekst. Widok ustawia się na pierwszy wiersz spełniający warunek wyszukiwania, wyróżnia wszystkie pasujące wartości i pozwala nawigować pomiędzy wierszami zawierającymi wyszukany ciąg (Ctrl-Góra, Ctrl-Dół). Widok w trakcie wyszukiwania wygląda tak:
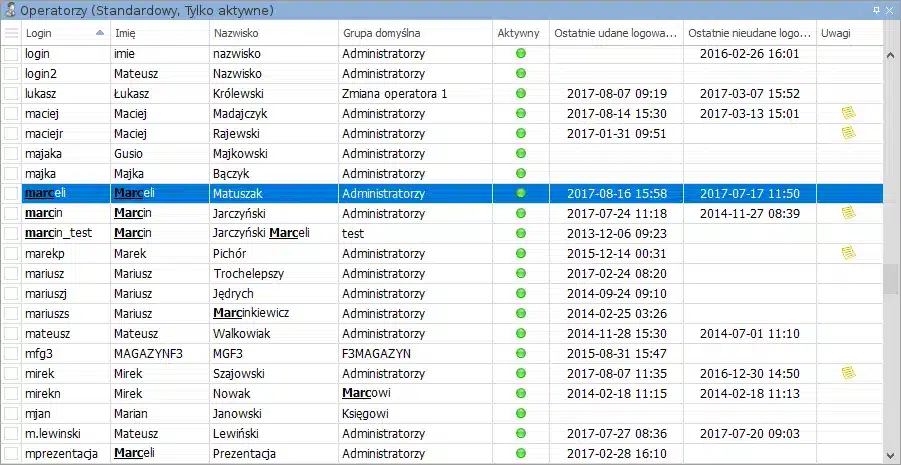
Wyszukiwanie takie cokolwiek funkcjonalne to jednak ma znaczącą wadę, działa wydajnie tylko dla małych zbiorów danych. Z jednej strony ponosimy koszt pobrania całego zbioru do warstwy klienta i to za każdym razem (każde pokazanie/załadowanie widoku), co jest obciążające dla wszystkich warstw infrastruktury, z drugiej strony przy dużych zbiorach danych oczekiwanie na ich wczytywanie, choć wykonywane przyrostowo, nie daje komfortu pracy.
Zatem mamy dobre rozwiązanie wyłącznie dla małych zbiorów, a co ze zbiorami dużymi, tu oczywiście rządzi wyszukiwanie po stronie serwera z wyszukiwaniem pełnotekstowym włącznie, i ono jest rozwiązaniem najbardziej optymalnym. Jednak! Czy nie można by zaprząc powyższego pomysłu także dla dużych zbiorów? Okazuje się że można. Tak właśnie działa „Doszukiwanie ekranowe”. Główne wyszukiwanie działa klasycznie, po stronie serwera, zapewniając wydajność i nie degradując skalowalności, ale jego wyniki zazwyczaj są już małe i je spokojnie można już przeszukać (raczej doszukać) „ekranowo” po stronie klienta, co razem jest i wydajne i wygodne.
Wyszukiwanie ekranowe ma jeszcze jedną wadę, nawet dla małych zbiorów występuję ciągłe pobieranie ich zawartości z serwera do klienta … a skoro już pobieramy te dane za każdym razem i to w całości, zachodzi pytanie jak często one się zmieniają? Dla wielu przypadków odpowiedź brzmi „nie często”. Dla takich zbiorów wyszukiwanie ekranowe jest optymalne (bo są małe) ale warto dla nich włączyć także mechanizm buforowania (bo są rzadko zmienne). Buforowanie danych wykorzystuje specjalizowany silnik pamięciowo-plikowy, który pozwala bez naruszenia zasobów lokalnych przechowywać na czas działania aplikacji klienckiej dane które nie zmieniają się zbyt często, z uwzględnieniem algorytmu LRU podczas przepełnienia. Pozwala to w ogóle nie angażować zasobów serwera w proces pobierania danych. Znacząco wpływa to na zwiększenie szybkości działania i zdolności do skalowania całego systemu.
Zachęcam do testowania w/w mechanizmów w nowej wersji Streamsoft VERTO.

Krzysztof Olszewski
Dyrektor Technologii i Architektury Oprogramowania
Krzysztof Olszewski
Dyrektor Technologii i Architektury Oprogramowania